Method
SDFit represents object shape via a morphable Signed Distance Function (mSDF) and jointly estimates 3D pose and shape by minimizing a render-and-compare objective over rendered mask, normal and depth maps. The pipeline has three modular stages — strong shape prior, retrieval-based shape initialization, and foundational-feature-based pose initialization — followed by joint iterative refinement.
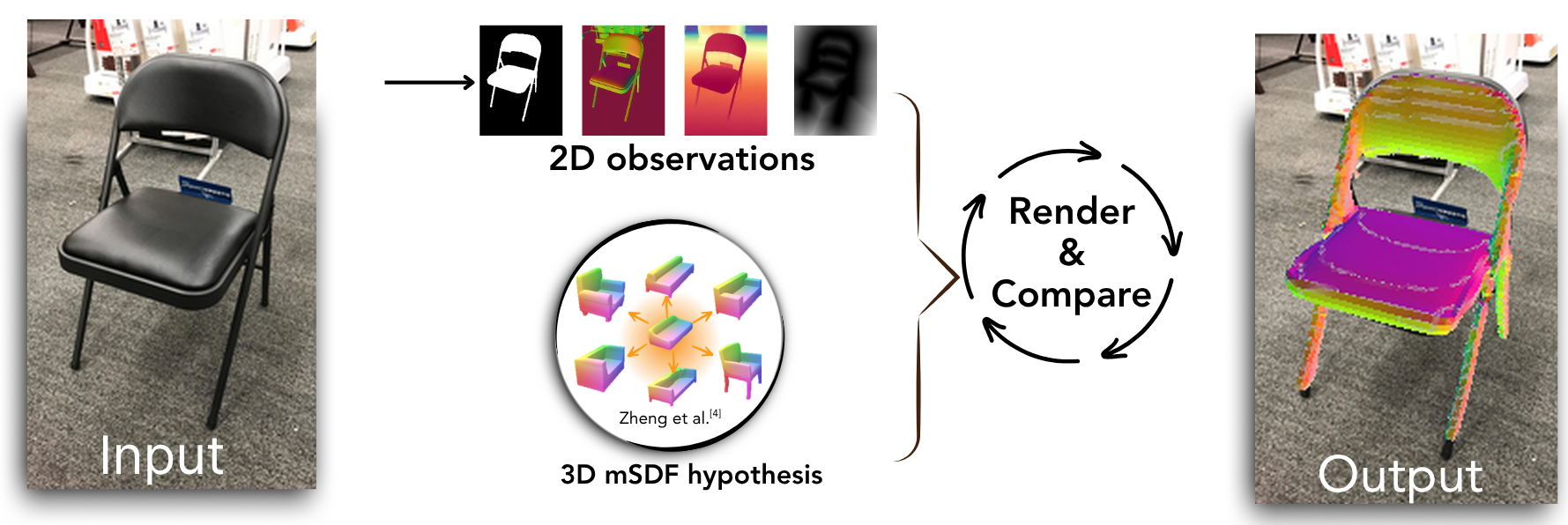
High-level overview of SDFit: shape initialization via retrieval (left), pose initialization via 2D–3D correspondences from foundational features (middle), and joint pose+shape refinement via render-and-compare (right).
① mSDF — morphable shape prior. We represent object shape with a learned, category-level morphable SDF (DIT). A compact latent code $z \in \mathbb{R}^{d}$ parameterizes a continuous SDF whose 0-level set defines the surface. This encodes the manifold of valid shapes, supports arbitrary topology, and yields dense correspondences across all morphed shapes — the same role SMPL plays for bodies.
② Shape initialization via retrieval. We embed both the input image and every training shape into OpenShape's joint 2D–3D latent space, and retrieve the mSDF shape whose embedding is closest to the image. This is fast, scales to large databases, and gives a strong starting hypothesis $z_{\text{init}}$.
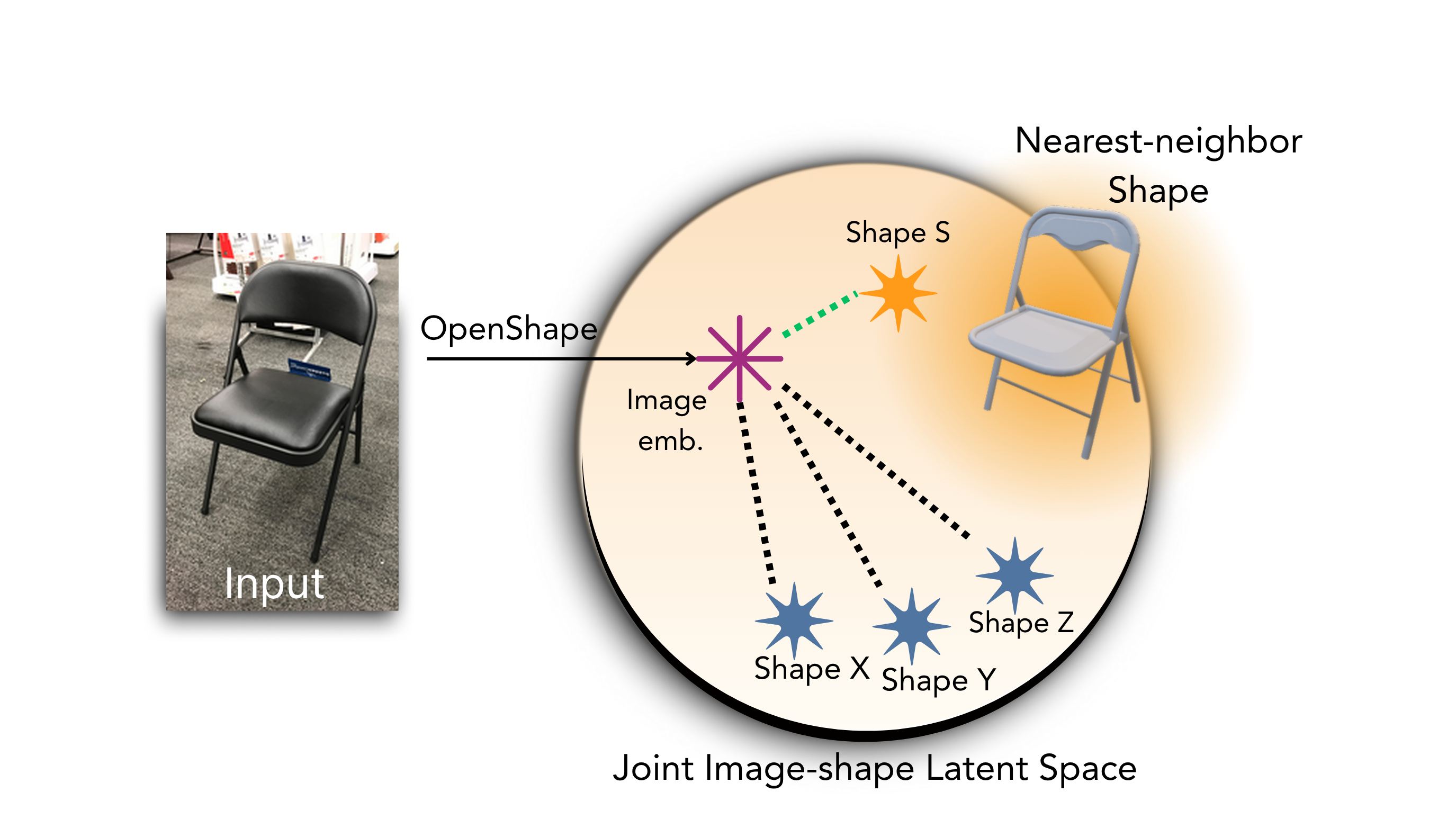
Shape initialization: retrieval in a joint 2D–3D foundational latent space.
③ Pose initialization via foundational correspondences. We decorate the initial mSDF shape with per-vertex ControlNet+DINO features, and match these to per-pixel features extracted from the image. This yields dense 2D–3D correspondences which, combined with intrinsics from PerspectiveFields, drive a RANSAC+PnP pose estimate — purely zero-shot.
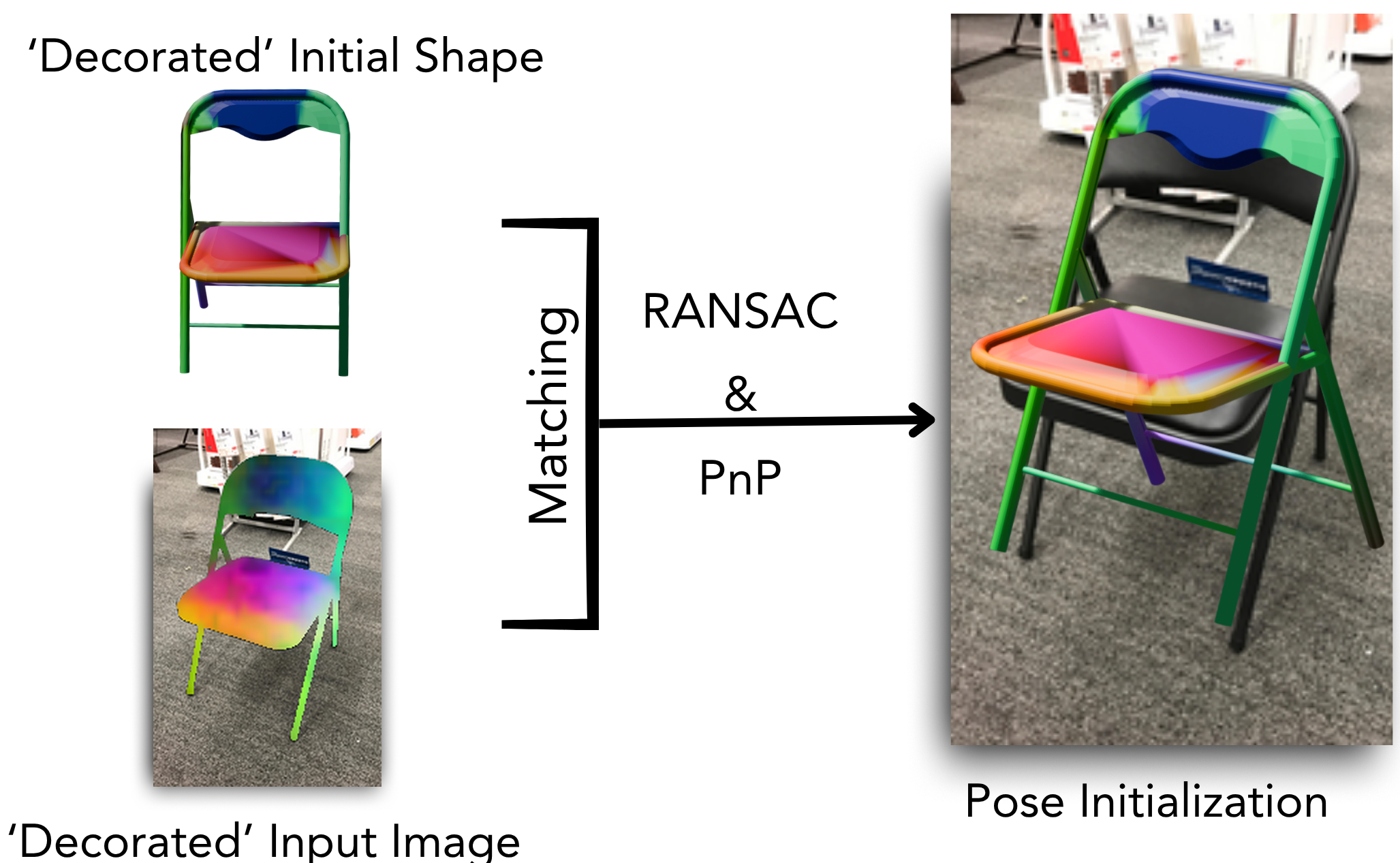
Pose initialization: dense 2D–3D correspondences from foundational features.
④ Render-and-compare refinement. Starting from $(z_{\text{init}}, R_{\text{init}}, t_{\text{init}})$, we differentiably extract a mesh (FlexiCubes), pose it, render (Nvdiffrast) and compare against image-predicted mask, normal and depth maps. Gradients flow back through the renderer into $(z, R, t)$, iteratively refining both pose and shape until convergence — with a canonical-space regularizer that allows topology to evolve (e.g. growing missing armrests) without falling into local minima.

